
Science des données appliquée à la langue – analyser des textes sans tout lire et tenir des feuilles de pointage. Le but est de trouver les dépendances et les sentiments en comptant les fréquences des mots.
Évaluer les textes ouText mining signifie littéralement en allemand: text mining. Il s’agit de la fouille ciblée d’informations avec des aides mathématiques. La machine lit, l’humain observe les résultats. La procédure classique d’analyse de texte depuis le début de l’alphabétisation vers 3000 av.J.-C. consiste à lire puis à écrire un ouvrage littéraire à ce sujet. Toute personne qui recueille des informations à partir de plusieurs sources effectue cette recherche de texte structuré. L’avantage de cette approche est que les gens peuvent le filtrer – quelque chose qui apparaît plusieurs fois n’est pas automatiquement pondéré plus lourdement, des erreurs sont découvertes.
L’exploration de texte au sens de «extraction de texte» est basée sur des quantités et des fréquences et fournit des informations quantitatives. Cela signifie que la tendance, la direction du contenu du texte est enregistrée par des nombres, des quantités et des positions. Une déclaration qui se produit dix fois est plus importante qu’une déclaration qui ne se produit qu’une seule fois. Cela donne à la langue comme moyen de communication une nouvelle interprétation. Les textes très volumineux et nombreux peuvent être analysés par machine. Une personne ne peut pas traiter de grandes quantités de texte. Les mineurs de texte ne travaillent pas avec des pelles et des pics, comme dans l’exploitation minière traditionnelle, mais avec des machines appropriées qui multiplient le travail humain.
L’analyse des humeurs et des tendances via le text mining est importante. Pour cette analyse, on attribue des groupes de sens ou des sentiments aux mots du texte. Les baromètres de satisfaction et les mesures de tendance peuvent être calculés à partir des avis clients et d’autres textes, ou de faux rapports peuvent être reconnus. Le logiciel standard R avec les packages tm ou le plus récent et plus complet tidytext [0] est très approprié pour cela.
Les analyses par grappes – ce qui se passe particulièrement souvent dans quel contexte – fournissent des informations importantes sur les tendances.
Voici un exemple du marché du travail qui a été délibérément maintenu simple.
Text mining pour des études de marché sur le marché du travail
Le paragraphe traite de l’exploration de texte en utilisant l’exemple du choix de carrière. Il suffit de collecter simplement les fréquences de mots et de former des groupes de mots pour identifier les tendances
Xing peut être utilisé comme source de données pour les décisions de carrière. De nombreux membres y ont affiché leur curriculum vitae, leurs intérêts et leurs offres. Xing autorise uniquement la fonction de recherche complète via les profils qui y sont stockés avec un compte premium payant. Sans Premium, vous ne pouvez rechercher que des noms. Pourquoi Xing? C’est l’équivalent germanophone de Linkedin. Linkedin est limité à la langue anglaise et est donc bon pour les relations internationales, tandis que Xing s’appuie sur la langue allemande et est local. Les membres sont invités directement sur place à saisir des CV corrects sous de vrais noms. Cela devrait vous aider à améliorer votre propre positionnement sur le marché du travail. De nombreux Allemands ont des difficultés avec les CV en anglais, c’est pourquoi Xing est plus significatif pour l’Allemagne.
Des parcours de carrière, des profils d’exigences et plus encore peuvent être sélectionnés à partir des profils, y compris des offres d’emploi ou des sites Web. Vous pouvez simplement les regarder et espérer des connaissances. Alternativement, des outils d’analyse de texte peuvent être utilisés, plus à ce sujet plus tard. Pour ce faire, cependant, les données doivent être résumées dans un fichier texte ou dans une base de données à part entière.
Le qualité des donnés
La valeur informative de cette recherche est limitée dans la mesure où dans le cas d’une recherche Xing, l’échantillon n’affecte que les membres Xing ou, à défaut, les membres LinkedIn pour la zone anglophone. Ce sont généralement des personnes qui souhaitent augmenter leur visibilité parce qu’elles sont à la recherche d’un emploi, qui recherchent généralement des contacts de loisirs (cela est également disponible via Xing) ou qui ont de nombreux contacts clients et fournisseurs qu’elles entretiennent via Xing. Les travailleurs acharnés heureux qui évaluent les données et les textes dans les coulisses sont moins courants sur Xing.
Les tendances peuvent être facilement lues à partir de textes – fréquences de mots plus élevées, plus de sens. On est étonné de voir à quel point les conneries au sens de mots de renforcement répétitifs sont particulièrement répandues dans la publicité. Les offres d’emploi ne sont pas épargnées ici non plus.
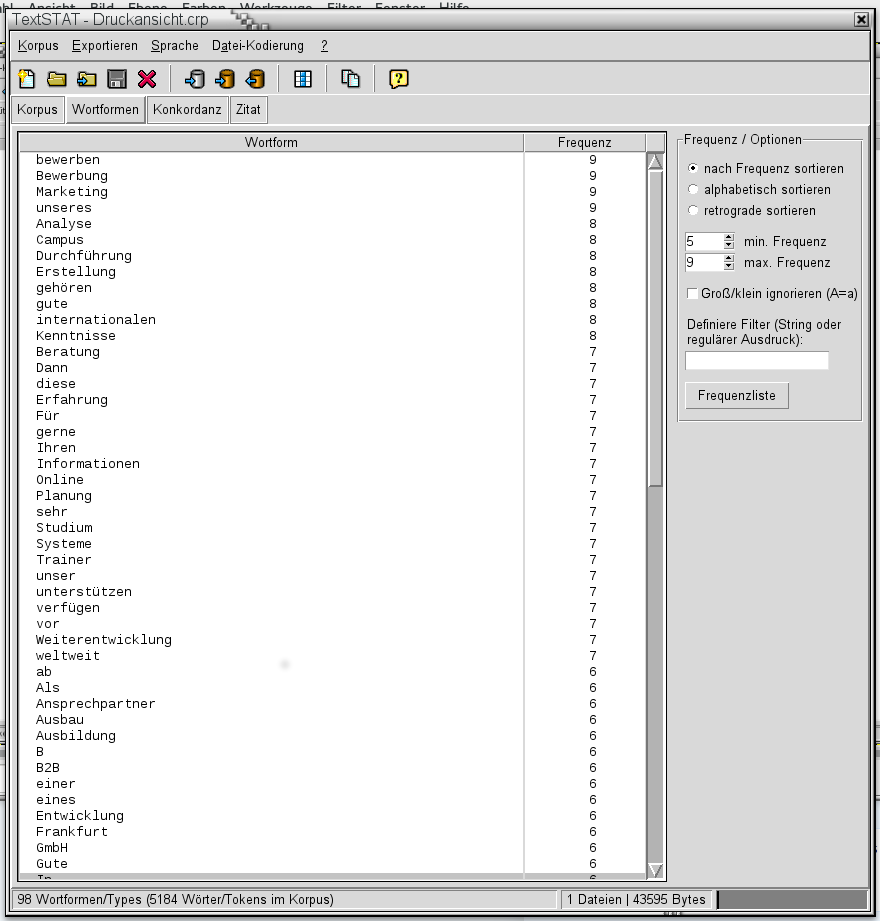
Évaluer les textes – procédure
mathématiquesIl existe des méthodes complexes, comme celle utilisée par Google, dans laquelle les mots sont pondérés en fonction du sens. Le moyen le plus simple d’évaluer le texte est de compter les mots. Textstat est recommandé si vous ne souhaitez pas le faire via des comptes payants avec des services spécialisés, mais plutôt avec l’aide de logiciels gratuits. Cela peut lire des documents Word et Openoffice ainsi que des sites Web et des fichiers texte et déterminer la fréquence des mots.
Le logiciel très simple pour les débutants est le paquet tm pour le logiciel de mathématiques R – j’aime bien l’utiliser. Le lien vous amène à l’autre introduction à l’exploration de texte avec R.
Le graphique suivant montre un exemple de text mining de 14 postes vacants pour les formateurs et des informations sur le marché.