Data Science auf Sprache angewendet – Texte analysieren ohne alles zu lesen und Strichlisten zu führen.
Text Mining bedeutet auf Deutsch wörtlich: Text-Bergbau. Gemeint ist das gezielte Ausgraben von Informationen mit mathematischen Hilfsmitteln. Die Maschine liest, der Mensch betrachtet die Ergebnisse. Das das klassisches Vorgehen der Textanalyse seit Beginn der Alphabetisierung um 3000 B. C. ist lesen und dann eine Literaturarbeit darüber schreiben. Diese strukturierte Textrecherche betreibt jeder, der Informationen aus mehreren Quellen sammelt. Vorteil dieses Vorgehens ist die Filterung durch den Menschen – mehrfach Erscheinendes wird nicht automatisch stärker gewichtet, Fehler werden entdeckt.
Text Mining im Sinn von „Bergbau im Text“ ist auf Mengen und Häufigkeiten abgestellt und liefert quantitative Informationen. Das bedeutet der Trend, die inhaltliche Richtung des Textes wird über Zahlen, Mengen und Positionen erfasst. Eine zehnmal vorkommende Aussage ist wichtiger als eine, die nur einmal vorkommt. Das gibt dem Kommunikationsmittel Sprache eine neue Interpretation. Maschinell können sehr große und viele Texte analysiert werden. Ein Mensch kann große Mengen Text nicht verarbeiten. Text Miner arbeiten nicht Schaufel und Pickel, wie im traditionellen Bergbau, sondern mit geeigneten Maschinen, die menschliche Arbeitskraft vervielfachen.
Bedeutend ist die Analyse von Stimmungen und Trends über Text-Mining. Für dieses Analyse ordnet man den Wörtern im Text Bedeutungsgruppen oder Gefühle zu. So können aus Kundenrezensionen und anderen Texten Zufriedenheitsbarometer und Trendmessungen berechnet werden oder auch Falschmeldungen erkannt werden. Sehr gut geeignet dafür ist die Standardsoftware R mit den Paketen tm oder dem neueren und umfangreicheren tidytext[0] .
Clusteranalysen – was kommt besonders häufig in welchem Zusammenhang vor – geben wichtige Hinweise auf Trends.
Es folgt ein bewußt einfach gehaltenes Beispiel aus dem Arbeitsmarkt.
Text Mining für die Marktforschung am Arbeitsmarkt
Der Absatz behandelt Text Mining am Beispiel Berufswahl. Hier genügt das einfache Sammeln von Worthäufigkeiten und Bildung von Clustern von Wörtern zur Ermittlung von Trends.
Xing kann als Datenquelle für Karriereentscheidungen[1] benutzt werden. Viele der dortigen Mitglieder haben dort ihre Lebensläufe, Interessen und Angebote hinterlegt. Xing lässt die volle Suchfunktion über dort hinterlegte Profile nur mit kostenpflichtigem Premium-Konto zu. Ohne Premium geht nur die Suche nach Namen. Warum Xing? Es ist die deutschsprachige Entsprechnung zu Linkedin. Linkedin beschränkt sich auf die englische Sprache und ist daher gut für internationale Beziehungen, während Xing auf die deutsche Sprache setzt und lokal ist. Die Mitglieder werden dort direkt aufgefordert, unter Klarnamen richtige Lebensläufe einzupflegen. Dies soll helfen, die eigene Positionierung im Arbeitsmarkt zu verbessern. Viele Deutsche tun sich mit englischsprachigen Lebensläufen schwer, weswegen Xing für Deutschland aussagekräftiger ist.
Aus den Profilen, auch aus Stellenanzeigen oder Webseiten können Karrierepfade, Anforderungsprofile und mehr ausgewählt werden. Diese kann man einfach anschauen und auf Erkenntnis hoffen. Alternativ lassens sich Textanalysewerkzeuge anwenden, dazu später. Dazu müssen die Daten jedoch entweder in einer Textdatei oder einer vollwertigen Datenbank zusammen gefaßt werden.
Wie gut sind die Daten?
Die Aussagekraft dieser Recherche ist insofern begrenzt, als im Falle einer Xing-Recherche die Stichprobe ausschließlich Xing-Mitglieder betrifft oder alternativ für den englischen Sprachraum Linkedin-Mitglieder sind. Das sind in der Regel Menschen, die entweder wegen Stellensuche ihre Sichtbarkeit erhöhen wollen, generell Freizeitkontakte suchen (auch das gibt es über Xing) oder viele Kunden- und Lieferantenkontakte haben, die sie über Xing pflegen. Glückliche Fleißarbeiter, die in Hinterzimmern Daten und Texte auswerten, sind in Xing seltener zu finden.
Trends lassen sich aus Texten gut ablesen – höhere Worthäufigkeiten, mehr Bedeutung. Man staunt, wieviel Bullshit im Sinn sich wiederholender Verstärkerwörter sich besonders in der Werbung breit macht. Auch Stellenangebote bleiben hier nicht verschont.
Texte auswerten – Verfahren
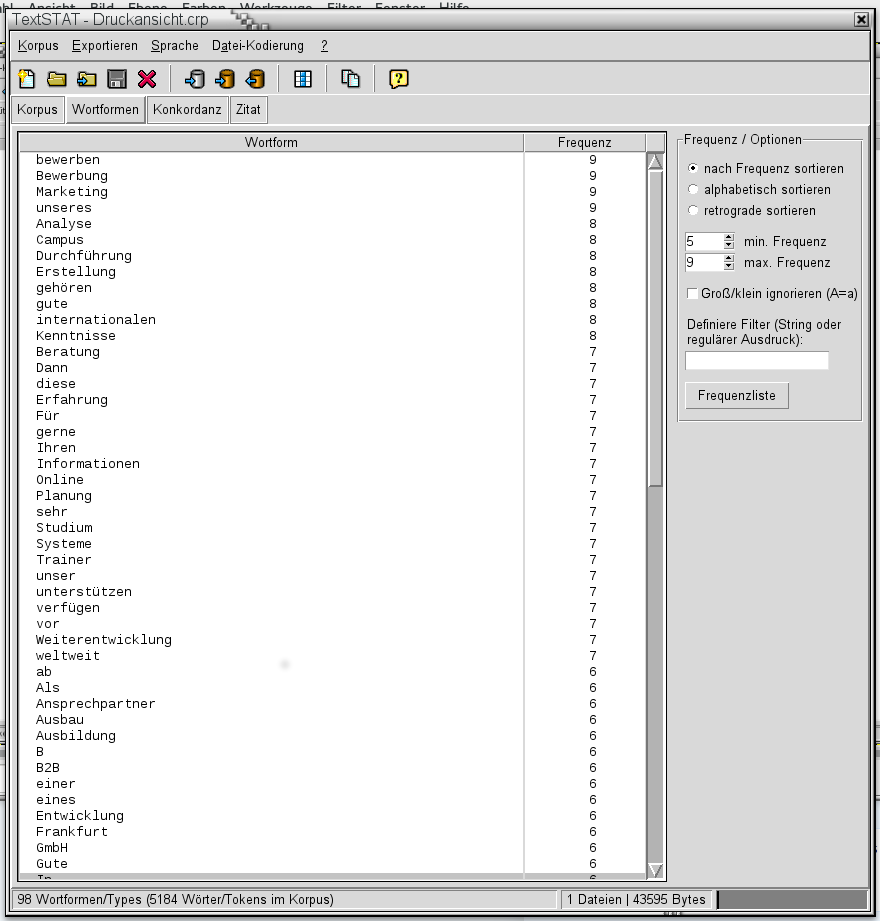
Es gibt komplexe Verfahren, wie etwa das von Google verwendete, in dem die Wörter nach Bedeutung gewichtet werden. Die einfachste Methode zur Textauswertung ist Wörter zählen. Möchte man das nicht über kostenpflichtige Konten bei spezialisierten Diensten machen, sondern mithilfe freier Software selbst, empfiehlt sich Textstat. Dieses kann Word- und Openoffice-Dokumente sowie Webseiten und Textdateien einlesen und die Worthäufigkeiten ermitteln.
Folgende Grafik zeigt eine beispielhaft Text Mining aus 14 Stellenangeboten für Trainer und Marktforscher.
———————————————-
- [0] Personal Coach Svenja Hofert argumentiert hier für eine datenbasierte Studien- und Berufswahl.
- [1] Analyseverfahren im Text-Mining – eine Übersicht (Fallstudienarbeit)
- [2]Die Auswertungen von Freitext mit tidytext für R ist ein breites Gebiet. Siehe auch im Tidytext-Manual